
Implementing Active/Active data center load balancing or disaster recovery seems to be an easy task for many of our partners and customers. Thanks to GSLB and NetScaler, it’s very easy, isn’t it? You just automatically distribute users among the data centers and replicate user data asynchronously in the background. Perfect solution, simple to implement and you’re properly utilizing all data center resources and evenly distributing users across both data centers simultaneously!
In the case where one datacenter is down, GSLB will redirect all users automatically to the secondary data center without any downtime requirements – users won’t even notice that the data center is not available anymore. Since images and data are automatically replicated, users will have access to the same set of applications and there will be no difference in user experience. When a user logs on, he will be automatically sent to the datacenter that is closest to him and least loaded based on GSLB load balancing, resulting in a situation where users are equally distributed across both datacenters, and ideally utilizing all the available resources.
You can find this utopian design diagram below:
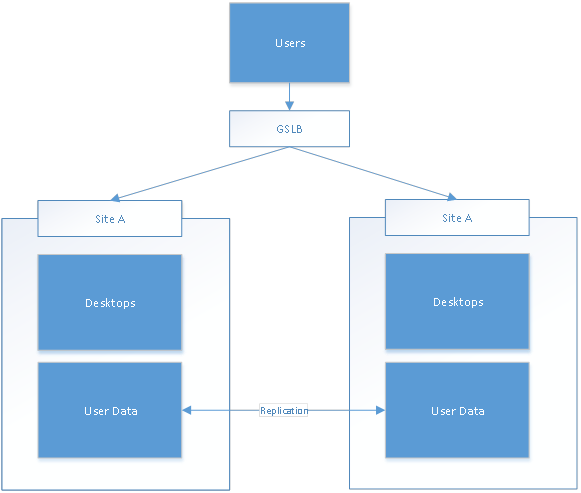
This sounds great, doesn’t it? It is simple, effective and seamless to the end users. I bet you have seen a customer attempt to do this or heard a sales person pitch GSLB (with NetScaler) as the simple and easy solution to make this happen. However, this is very, very dangerous!!! In the few paragraphs above, I’ve made all the common mistakes related to the active/active data center load balancing and disaster recovery planning. Let’s discuss the issues and why this design will not work.
User data replication
There is only one scenario where an active/active datacenter design is actually quite easy to implement. The requirement is simple – you simply need to have zero personalization requirements and not provide users with ability to make any configuration changes or allow them to create any documents or persistent data. Simple, right?
In case you would like to provide users with ability to have any kind of persistent data (be it profile, home directory, shared department drive, etc…), the situation gets a lot more complicated. Long story short – active/active replication is not supported by Microsoft or Citrix. Any supported scenarios assume that you’re using only one-way replication and that only one copy will ever be active at any point in time. In order to support active/active replication, you would need to have distributed file locking, which is not available with DFS-R.
If you really plan to implement an active/active datacenter, focus on the user data first before making any further plans. If you cannot find a satisfying answer for this problem, a truly and purely active/active implementation is probably not the right solution for you.
Some people might say that while active\active replication is not supported, it doesn’t mean that it’s not working. Believe me, in this case there is a very good reason why active/active replication is not supported for user data. If your profile vendor is telling you otherwise, you should be very careful. If your block-level storage vendor tells you they can replicate the user data as well in an active-active scenario, you should be even more careful!
As a rule of a thumb – never plan to have multiple access points to the same data by the same user.
Dynamic distribution of the load
As described previously, the biggest problem with an active-active data center or DR setup is access to the user data. It is not feasible to have a scenario where users are dynamically distributed across datacenters with multiple copies of user data being written and replicated simultaneously. As an alternative, you can assign users to a specific datacenter instead (also called sticky users).
This is typically done through Active Directory group membership. So, will a GSLB load balancer (like NetScaler) automatically check the user group membership and point a user to the correct datacenter? Unfortunately no – since GSLB is primarily DNS and network based, there is no way for NetScaler (or any GSLB solution) to actually check the user group membership before returning a proper DNS entry.
Another important limitation to understand is that you need to be able to handle disconnected sessions. A user will connect to datacenter A, disconnect and logon again from another location. Chances are that he may be redirected to datacenter B – instead of getting reconnected to his existing session in datacenter A. He will now start a new session, which is very bad!
As a result, you need to assign users to a primary datacenter and the assignment needs to be static. Dynamic distribution of the users is possible only with users that have no user data – and at the same time, disconnected sessions should be terminated after a very short timeout. This is almost never the scenario for users accessing VDI or hosted desktops!
Application Backends
If you are lucky enough and don’t have to care about user data, there is one more complication on the road. Citrix XenDesktop is effectively acting as a frontend service, however desktops without user data and without applications with application data are not typically very useful. Keep in mind that user data and application backends are much more than profiles, home directories and shared network drives. The critical application backends that make up a productive user desktop also typically include items such as the following:
- SharePoint or other portals and document repositories
- Email backends such as Exchange
- SQL Server databases hosting numerous business applications such as SAP
- Etc…
When designing a disaster recovery strategy, I start the discussion asking the following questions:
- What exactly needs to be recovered during the DR process?
- Is 100% DR capacity required, or will the DR environment support a percentage of the users?
- Should all applications be available, or a subset of applications that are critical to the business?
- Are recovery procedures in place for all such applications and are they capable of running in active\passive mode?
- Once access has been disabled to the active data center, how long does it take to prepare the application backends in the secondary data center?
- Is failover manual or automatic for the application backends? How long does it take to finish a recovery procedures for applications backends?
These are just few of the questions that are critical for disaster recovery planning. With an active/active data center desing, the questions are slightly different, since you also need to understand whether or not your applications are designed to work in active/active mode. And majority of the applications are not designed for this mode of operations.
Chances are that your applications from the secondary site will need to communicate with the backend servers located in the primary datacenter if an application level backend failover had not yet occurred. Have you considered what this active/active design could do to your bandwidth requirements? Can you see the problem here in the diagram below if an application backend is not active/active?
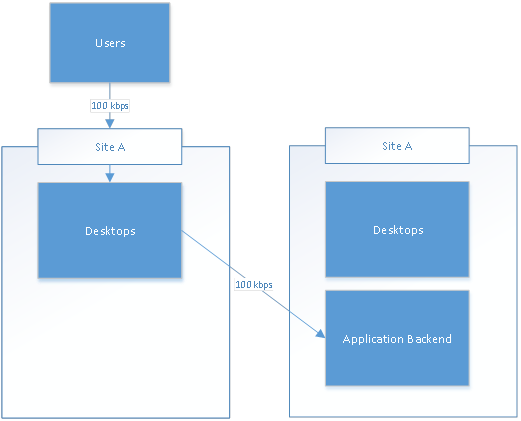
Automated Failover
To properly architect a DR solution, there are two important factors that you should focus on to understand the requirements:
- Recovery Time Object (RTO): RTO is the duration of time within which the service should be restored after a disaster.
- Recovery Point Objective (RPO): Maximum tolerable period for which data might be lost during recovery process.
In short, you want to keep both values to the minimum. And of course, another aspect that comes to play in here is Total Cost of Ownership (TCO). Usually (not always), the lower the RTO/RPOs are, the higher the TCO of the solution. If you require low RPO, that means constant replication of the data, which results in higher bandwidth requirements and higher TCO.
Now, another relationship that might not be so clear is that lower RTO can result in higher RPO. Consider example where Contoso replicates the data after business hours so as not to impact production WAN during the business day and on the average it requires 2 hours to replicate the daily changes. If RTO is 3 hours, they could replicate all the data to the backup site prior to transferring all the users even if the outage occurred during the day. As a result, RPO in this situation could be zero, as all user data could be replicated in less than 3 hours if required. However, if Contoso decides that they need a near zero value for RTO, instead of replicating all the user data before failover, they will need to discard it and failover immediately. Now their RPO is potentially up to 24 hours, but RTO is close to zero. This is based on an assumption that we still are in control of the data and can decide whether or not we plan to properly finish with the replication.
Realistically, you should plan a few hours for the proper failover. Failover can typically be divided into two parts.
Step One: Active Data Center Becomes Passive
The first part of the failover process is to disable access to the primary datacenter. This process typically involves the following high level steps:

The time required for each of these steps can differ. For example you might decide to force termination of existing sessions, but you’re risking that users will lose their data. Or you might decide for a more gentle approach, notify users to finish their work and let them finish their sessions. There are few associated decisions – for example do you want to block access for all users, or do you plan to drain existing users?
Step Two: Passive Data Center Becomes Active
Once the datacenter doesn’t have any active connections and user data is either properly replicated or you’ve decided to cut them off (increasing the RPO), it’s possible to proceed with the second part of the failover, activating access to the backup datacenter.

As you can see, there are few different steps you would need to take (and we haven’t mentioned the backend application servers) and there might be a requirement for ad-hoc decisions during this process. If you try to fully automate the failover, you’re probably just automating the disaster instead of automating the disaster recovery. While all the steps can be either fully or partially automated, at least the Go/No-Go decision should always involve manual interaction and proper decision making process.
While I’m a big fan of automation, there are certain decisions that should never be automated. David E. Hoffman wrote the following about Dead Hand (nuclear control system developed by the Soviet Union during the cold war):
“Now, the Soviets had once thought about creating a fully automatic system. Sort of a machine, a doomsday machine that would launch without any human action at all. When they drew that blueprint up and looked at it, they thought, you know, this is absolutely crazy. We need a human firewall.”
Please don’t build a doomsday device in your datacenter. You need a human firewall as well.
Summary
To quickly summarize this blog post, while an active/active data center design sounds great, it is a lot harder to implement than most people realize and there are many obstacles on the road. You should make sure that you fully understand the challenges before you decide to implement active/active solution.
Lessons learned:
1.) Active-Active is a lot more complicated than is seems and requires careful planning.
2.) User profiles/redirected folders, home directories, shared drives, etc… don’t support active-active replication.
3.) You always want to assign users to specific datacenter instead of using dynamic distribution.
4.) Failover should always be manual process.
5.) Make sure that your applications can work in active/active mode as well.
6.) Expect downtime during failover. Instant failover can cost your users’ data
7.) Active/active and DR implementations are much bigger than Citrix. “Citrix” is the easy and inexpensive part to be honest – the backend user data and applications are the difficult and expensive parts.
8.) Our friends at Microsoft and your favorite storage vendor (i.e. EMC, NetApp, etc.) should be engaged as part of these conversations, since doing this successfully really involves careful planning with all the appropriate parties. Again, Citrix is just a piece of the puzzle.
I hope you’ve enjoyed reading the first part of this blog post and are looking forward to the second part. In the next post, my colleagues and I are going to discuss different ways an active/active data center and DR strategy can actually be designed and implemented and the different options to make it work.
I would like to help my colleagues Dan Allen, Andy Baker and Nicholas Rintalan that have done tremendous job supporting me and providing me with a great feedback.
UPDATE (4/13/2014): Theory is nice, but real life implementation is priceless! In an effort to get closer to the mythical unicorn that is active/active GSLB for XenDesktop, my colleague Eric Jurasinski has just released a blog on “homing” users to specific data centers and failing them over in the event of an outage. You can find the blog here: /blogs/2014/04/09/activeactive-gslb-for-xendesktop-a-practical-approach-part-1/
Stay tuned!
Martin Zugec
Virtual Desktop Handbook
Project Accelerator
Follow @CTXConsulting

