
Before reading this article, you definitely want to check out the amazing whitepaper from Dan Allen called Advanced Memory and Storage Considerations for Provisioning Services. I’m not going to explain the basics here, so I recommend you do your homework first.
I’m going to write a follow up blog post later on. This first part will focus on the theory, while the second part will focus on how you can use this knowledge in the real life, how to properly determine the amount of memory needed for PVS server and which tools can help you during testing and troubleshooting.
Lie-To-Children
Back in 2000, gentlemen Ian Steward, Jack Cohen and Terry Pratchett came up with term “Lie-To-Children” in their marvelous book Science in Discworld (which I can recommend to everyone). According to Wikipedia, a lie-to-children is an expression that describes the simplification of technical or difficult-to-understand material for consumption by children. The word “children” should not be taken literally, but as encompassing anyone in the process of learning about a given topic, regardless of age.
There are many “Lies-To-Children” in IT all around us, we just often don’t recognize them anymore. When we are trying to explain something to the end users or family relatives (especially older ones), we often use them to explain complex technical problem and many times we don’t even realize that it’s not 100% true what we are saying. It’s true enough and if needed, we can always explain the details later on, right?
Developers tend to improve the product with each and every version – and sometimes (especially if we’re talking about kernel components), these changes are very complex in nature and evolved over years into something that cannot be easily explained in few sentences. Guess what happens when developer is trying to translate complex MSDN article with tons of references to APIs to the regular IT Pro? That’s right – it’s time to come up with just another lie-to-children.
One of the most common examples is related to the free memory – you want to have as much free memory as possible to keep your system responsive, but is it really so? In fact free memory is a bad memory – it’s wasted and useless. You don’t want to have free memory – you want to use it as much as you can. I can highly recommend to series from famous Mark Russinovich called “Pushing the limits of Windows”.
Provisioning Services
As we all know, Citrix Provisioning Services allows us to stream operating systems and enables single image management. The way how I like to think about it is that PVS is a super cheap cache that sits between your expensive storage systems and the target devices that wants to read from this storage. From this perspective, PVS is not as magical as you would expect – we simply use the Windows caching mechanism to our advantage, that’s why I’ll spend most of the article discussing the internal Windows caching mechanism.
One of the most common questions we’re frequently being addressed with is “how much memory should I assign to my PVS servers”. Answer (and you probably don’t want to hear that) is “It depends”. If you really want to get some answer, it would be “your memory in use + total size of all your VHD files” – and this would of course mean that you’re wasting your resources and not allocating them effectively. In order to understand this rather vague answer, let’s have a look at how Windows caching mechanism works internally.
If you’re looking for a rule of thumb to start with testing, you can use following formula:
4 GB + (#vDisksClient * 2GB) + (#vDisksXenApp * 5GB)
We use 2GB for client platform like Windows XP or Windows 7 and 5GB for XenApp servers (assumption is daily reboots for clients and weekly reboots for servers).
Windows Caching
Years ago, I can imagine there was discussion between Windows engineers – there are tons of free memory out there and it’s simply wasted, shouldn’t we do something with it? For example, we could use it to cache some information, right? If we use finish with processing of some data, instead of expensive flushing of the pages, we will just leave it where it is – and maybe use it later on. This day was very important for us, if known, we should mark it in our calendars and celebrate it each year. Not only it greatly improved the responsiveness of overall system, but it also allowed us to develop one of our products – Citrix Provisioning Services.
In Windows, majority of file system operations are automatically cached – and this applies to both read and write operations. You can divide memory in your system to few different categories (I’m completely ignoring physical vs. virtual memory here, focusing on physical memory only – paging lists are stored only in physical memory).
- Hardware reserved
- In use
- Modified
- Standby
- Free
We can further divide this list into three different areas from perspective of caching manager:
- In use (hardware reserved + in use) – here be dragons, beware, don’t touch, don’t care
- Cached (modified + standby) – here are your cached data, recycle if needed
- Free – wasted, try to find any use for it
“Cached” memory is memory that is not immediately required by any active process, but Windows used it for caching some information instead. If needed however, it can be easily repurposed and assigned to any process that requires more memory (free memory will be assigned first though). Cached memory + free memory is called available memory.
The easiest way (and yes, it’s a lie) how to explain the difference between standby and modified page lists is that standby is read-only store, while modified is used to cache write operations.
When you read something from your disk, pages are automatically stored in the standby memory list – so if you access this data again, you can avoid expensive IRP (IO Request Packet) and you can retrieve it from the fast memory instead. Windows is using standby for read-only caching – this includes not only frequently accessed data, but also data fetched by SuperFetch.
When you modify this data (or any other data), modifications are stored in memory in Modified list and are being written to the disk when possible. The principle is rather simple to understand –because it makes a lot of sense. For example, when you’re copying a file from a network share – during copy operation, pages are automatically written into modified list, lazy writer will take those pages, write them to disk and automatically move pages to standby list. So when you open the file, it’s actually opened from memory and there is no need to read it from disk. “Flushing” of modified pages is not done all at once – it is dynamic process, controlled partially by scheduled lazy writer and partially by current conditions of operating system (for example writer is spawned when memory is overcommitted).
Important lesson – modified list is not just a buffer – data that are written here are moved to read-only (standby) memory when the operation is finished. If you see 2GB of data in standby memory before copy operation, 100MB in modified list during the copy operation and 2GB of data in standby memory after copy operation, it’s doesn’t really mean that the standby memory is the same as before the copy operation. Instead of copying of the pages, they are simply moved from one list to another.
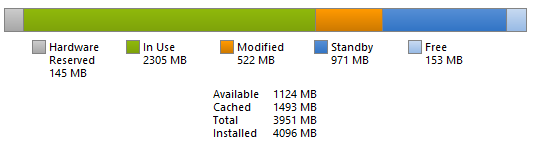
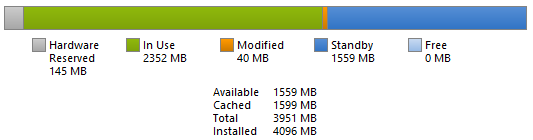
Now, what many people are struggling to understand is that technically you’re not caching complete files – caching manager is using the virtual block principle; therefore it allows you to cache only certain parts of the file. As a developer, you can modify this behavior (typical example – when you’re copying large files, read-ahead is used and data are read sequentially based on recognized pattern). Each block is identified by its address and offset – in the end (and especially with random access solution like Provisioning Services), your mapped file can look more like an emmental cheese (or Swiss cheese for all you Americans!). This is also how SuperFetch works – it doesn’t need to understand that when you click on “I agree”, you’re going to click on “Next”. It simply needs to know that when virtual block at address “A” with offset “B” is requested, the next request will be address “C” with offset “D”.
The best way how to think about standby and modified page lists is that Windows is using them to store the data that could potentially be needed later on. There is no harm to keep them around a bit longer, just in case we will need them.
Now, this is again lie-to-children – the story is not over yet. When you start explaining cache manager to someone, one of the obvious questions is related to the fact that your valuable data (for example indexes or system libraries) could easily get overwritten by one large VHD file that you don’t actually plan to run until next year. Internally, there are 8 different standby lists with different priorities (0-7 – the higher the number, the higher the priority). For example priority 7 is static set generated by clever folks at Microsoft, priority 6 are SuperFetch VIP residents, priority 5 is your standard priority and lower priorities are used by low priority processes or read ahead operations.
Consequences for PVS
There are many aspects when understanding the Windows caching manager can help you in properly designing the PVS environment. From the most obvious example (how to do proper sizing of PVS memory) through regular maintenance tasks (how to copy vdisks between servers) to less obvious topics (should you delete vDisk when you don’t plan to use it anymore?).
Replicating vDisks between servers
Majority of Windows and 3rd party utilities are using buffered IOs to perform read/write operations. The reason is rather simple – this functionality is provided by Windows APIs, therefore it doesn’t really matter if you use Explorer, Robocopy or any other tools. Some utilities (Xcopy, RichCopy and the latest version of Robocopy) support switches for unbuffered copy operations. But do you want to use buffered or unbuffered IOs with PVS?
What happens in case you are using the good old active/passive vDisk approach? You have updated your .vhd file on your master server, now you want to replicate it to the rest of the servers. Most of the times, it’s actually buffered IO you want to perform – because unbuffered IOs are used only in case you don’t plan to access the resource afterwards, which is not the case. Copy operation should go through priority list 2, therefore copying large VHD files shouldn’t affect your running target devices (most of VHD blocks will be cached with priority 5). And since you plan to switch your target devices to this newer version of VHD files, copy operation will actually pre-cache this VHD file for you.
It is also important to remember that it takes two to tango. When you copy vDisks from PVS A to PVS B, both servers are affected by this operation. The default behavior when you use unbuffered copy operation is that while server A will not use standby memory for copy operation, server B will proceed as expected – it will save the pages to modified list and transfer them to standby list once the writer is finished.
It’s also important to stress again the fact that this caching mechanism has nothing to do with Provisioning Services, it’s simply functionality of operating system that we take advantage of. That means there is another side effect here – since target device is probably also Windows based client, this means that it’s also using standby memory for caching. That is why you don’t see constant network traffic from PVS server towards the target device – target device will simply use its own standby cache for caching all read operations from PVS server and recycle that cache instead of constantly querying the server. In an interconnected world of Windows devices, one file can easily be cached on multiple devices.
When file is deleted, all cached entries are automatically flushed – so if you don’t plan to use those large files anymore and you want to clear your cache, simply delete them.
When target device cache is full, the standby cache of provisioning server is not as important as you would expect. You can use this behavior to your advantage when you use active/passive versioning with two different vDisks – once your devices are running steadily, you can easily swap the vdisks even if your PVS server doesn’t have enough memory to operate two fully blown vdisk files (of course, you want to carefully test this scenario for negative impact before you use it in your production environment).
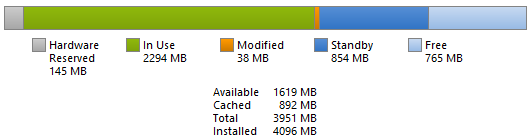
Pagefile sizing
Notice another pattern here – PVS server is designed to have large amounts of “wasted” memory, so Windows can take it and use for caching of vdisks. If you have seen the blog post from Nicholas Rintalan (The Pagefile Done Right!, one of the articles with “must read” tag), you already know that there is no magic formula to calculate the proper pagefile size. What you can actually say is that if your commit charge doesn’t increase, the larger the memory, the smaller the pagefile should be. One of the perfect examples is PVS server – you can hardly find any example where huge memory can be accommodated with a very small pagefile.
Help – my server has 128GB of memory, but none is free
This is very common concern – almost as common as people complaining about no free memory in Windows Vista. Based on what we’ve been discussing here, Windows will try to keep the amount of free memory to minimum. Forget about emptying standby cache – this could potentially work back in NT era, but operating systems these days knows better than us what to do and caching and memory is no longer a static process that can be tweaked by some magical configuration changes.
However, you might want to check what’s stored in the memory – for example some scripts that are calculating hashes or misconfigured antivirus can also affect your standby cache. If you want to dig deeper, subscribe to Citrix RSS and wait for next post on this topic. We are going to leave the theory behind and dig deep into practical aspects of Windows caching and PVS servers.
Ehm, so what does that mean actually?
To summarize:
- Majority of copy operations in Windows are cached in memory (even local operations)
- Free memory is bad memory and it’s completely normal if your PVS server has little free memory.
- Cache manager is caching blocks, not the whole files, so you don’t need to plan for caching the entire VHD in memory
- Buffered\Unbuffered copy operations can affect your cache, however the impact is much smaller (and can be actually beneficial) than most people think
- There are different priorities for cached data, so you don’t need to be afraid that copy operation will flush your cache completely
- Not only memory sizing of PVS server is important, but also memory sizing of target devices. If you leave no memory for caching on target devices, they will need to perform more read operations from PVS server itself
In the next part of this blog post, we’re going to have a look at some tools that can help you with determining the proper size of PVS RAM and gives you some overview of how your cache is actually being used. Stay tuned.
Last but not least, I would like to thank Dan Allen and Nicholas Rintalan for great feedback, it helped me a lot while I was preparing this blog post.
UPDATE: You can find 2nd part of this article here
Martin Zugec

